NLP概念厘清
ACL
Association for Computational Linguistics (ACL),NLP领域顶会之一。念起来直接读字母即可。
Regional associations related to the ACL include:
- EACL : The European Chapter of the ACL
- NAACL : The North American Chapter of the ACL
- AACL : The Asia-Pacific Chapter of the ACL
Adaptive fine-tuning
一般的fine-tuning步骤是利用预训练好的模型直接在下游标定好的任务中进行精调,而adaptive fine-tuning则是在插在pre-training和task specific fine-tuning中间,在与目标任务更接近的规模更大(相对目标任务数据集)的数据集进一步pre-train,从而使得模型更适应目标任务。以新闻分类任务为例,预训练的语言模型对新闻类的任务domain之间有gap,所以可以在大规模的新闻预料库上进一步预训练语言模型,最后再在新闻分类数据集上进行精调。See more in this blog.
Anaphora
anaphora解析是找到名词短语的引用的问题。例如,“李雷闯祸了,他知道情况很严重。“其中,”他“引用的”李雷“。
Autoregressive model
自回归模型,是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即x1至xt-1来预测本期xt的表现。这是从回归分析发展而来,只是不用x预测y,而是用x预测 x(自己),所以叫作自回归。例如,语言模型中一个一个地预测下一个词,以及图像生成中一个个地生成像素,这些都属于自回归模型地范畴。
Back translation
一种翻译增强策略。例如,将原始中文T1翻译为英文,再将英文翻译回中文T2,即便T1和T2的表达不一样,但它们在语义上应该是一致的,如果不一致,则说明我们的两个翻译模型中的至少一个出了问题,从而进行可以对翻译模型进行调整。See more in this blog.
BLEU
Bilingual evaluation understudy, 双语互译质量评估,是用来评估机器翻译质量的公式。音同“blue”,详见博客。
Coling
International Conference on Computational Linguistics,NLP领域顶会之一,音同“kouling” (watch in this video)
Contextual representations
对static embeddings而言,每个token对应的向量表征是一样的;而contextual representations中token的向量表征由它在语句中的位置以及它临近的文本所决定,是动态变化的。
更多可查看该论文,其不但阐述了static embeddings和contextual representations的概念,而且介绍了一种把contextual representations转换为static embeddings的方法。
Continuous bag of words (CBOW)
训练word2vec的一种方法,如下图(from word2vec paper)所示,根据周围的token预测中间的token:

Continuous bag-of-words
其中,continuous表示是连续的表征,bag of words是因为该模型中输入词语的位置对输出无影响,是某种意义上的词袋模型。
Coreference resolution
共指解析,是查找文本中引用同一实体的所有表达式的任务。例如,“李雷和韩梅梅一起上初中,雷从小就认识梅梅的妈妈。”这句话中,李雷和雷指代同一人,而韩梅梅和梅梅指代同一人。See more in the coreference lecture in Stanford CS 224N.
Distant Supervision
远程监督,一种用于实体关系数据标定的半监督方法。一句句话去标定实体之间的关系是很昂贵的事情,远程监督则利用一种标签扩散的方式减轻标定成本。例如,在《红楼梦》中,由于我们知道贾政和贾宝玉是父子关系,所以所以同时出现了贾政和贾宝玉的句子则可认为是”父子“关系样本。这种标定方式包含噪声,因为不是所有包含贾政和贾宝玉的句子都能判断出他们的父子关系,所以需要通过其他手段进行数据清洗。See more in this paper.
EMNLP
Empirical Methods in Natural Language Processing,NLP领域顶会之一。念起来直接读字母即可。
Grounded language modeling
Grounded language models represent the relationship between words and the non-linguistic context in which they are said.
Grounded language models are based on research from cognitive science on grounded models of meaning. In such models, the meaning of a word is defined by its relationship to representations of the language users’ environment. Thus, for a robot operating in a laboratory setting, words for colors and shapes may be grounded in the outputs of its computer vision system; while for a simulated agent operating in a virtual world, words for actions and events may be mapped to representations of the agent’s plans or goals.
- speakers 将非语言表征作为输入,生成文本,see more in this video。
- listeners 语言作为输入,获取关于世界的状态, see more in this video。
See more in this paper.
In-context learning
上下文学习是自然语言理解中最近的一种范式,其中大型预训练语言模型(LM)观察一个测试实例和一些训练示例作为其输入,并直接解码输出而不对其参数进行任何更新。详见GPT3论文。
Inductive bias
归纳偏置,是模型为了泛化到新输入而作的一组假设。例如,通过多任务学习获得的归纳偏差鼓励模型更喜欢解释多个任务的假设(参数集)。See more in this blog.
NAACL
North American Chapter of the Association for Computational Linguistics. NLP领域顶会之一。音同“nakou” (watch in this video)。
Natural language inference
Natural Language Inference or Recognizing Textual Entailment (RTE) is the task of classifying a pair of premise (前提) and hypothesis (假设) sentences into three classes: contradiction, neutral, and entailment (蕴涵).
验证模型是否有common sense reasoning的任务。
See more in this blog and this video.
Paraphrase
转述,一句话换一种表达,保持语义不变。例如,把”我爱你“转换成”今夜月色很美。“
Perplexity
困惑度,可用于评价语言模型的建模能力,困惑度越低,语言模型的表征能力越强。详见Perplexity of fixed-length models (huggingface.co)。
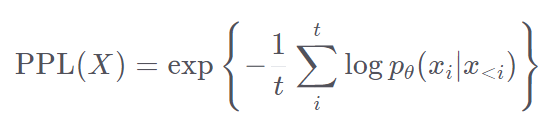
Prompt
Prompt有迅速和提示等义,此处作提示解,为了下游任务设计出来的一种输入形式或模板,它能够帮助大规模预训练模型“回忆”起自己在预训练时“学习”到的东西。
Scheduled sampling
Scheduled Sampling是一种解决训练和生成时输入数据分布不一致的方法。 在训练早期该方法主要使用目标序列中的真实元素作为解码器输入,可以将模型从随机初始化的状态快速引导至一个合理的状态。 随着训练的进行,该方法会逐渐更多地使用生成的元素作为解码器输入,以解决数据分布不一致的问题。 标准的序列到序列模型中,如果序列前面生成了错误的元素,后面的输入状态将会收到影响,而该误差会随着生成过程不断向后累积。 Scheduled Sampling以一定概率将生成的元素作为解码器输入,这样即使前面生成错误,其训练目标仍然是最大化真实目标序列的概率,模型会朝着正确的方向进行训练。详见论文。
Skip-Gram
训练word2vec的一种方法,如下图(from word2vec paper)所示,根据中间的token预测周围的token:

Skip-gram
名称的由来原文中并未解释,但应该与n-gram模型有关,n-gram表示n个连续的token,此处通过中间的token预测周边的token,有“skip”的意思。
Support
测试集中某一类样本的个数,用以表示测试集的规模。
Teacher forcing
Teacher forcing is a strategy for training recurrent neural networks that uses ground truth as input, instead of model output from a prior time step as an input.
See more in this blog.
Winograd sentences or schema challenge
Winograd模式是一对句子,它们仅在一个或两个单词中有所不同,并且包含歧义,该歧义在两个句子中以相反的方式解决,并且需要使用世界知识和推理来解决它。该模式的名称来自Terry Winograd的一个众所周知的例子:
市议员拒绝向示威者发放许可证,因为他们[害怕/鼓吹]暴力。
如果这个词是“害怕”,那么“他们”大概是指市议会;如果是“提倡”,那么“他们”大概是指示威者。